Paper Cut Audio Editing for Radio Journalism
April 1st 2024 | #English #Open Source
Update 08. April 2025: There's been some changes in the commands needed, so I've updated this write-up accordingly.
tl;dr: It's no longer necessary to slowly listen to audio for editing interviews, you can do it with simple text files. Work as fast as you can read!
There is now a way to edit (automatically generated) audio transcripts in a text editor like Vim(!) and then tell the computer to apply all the changes in the text to the corresponding audio(s). No more slow cuts in audio tools like Audacity/Tenacity or painful transcriptions by hand. Instead fast, efficient and nerdy. This changes my radio production workflow fundamentally. And the best part is, we don't need expensively licensed software from some startup to do it, it's possible with open source tools that are easily available and adaptable to our specific needs.
Disclaimer: The following text describes a workflow that might seem daunting for people who don't use linux or have never opened a command line interface. I've tried to make it an interesting read anyway, for the less technically inclined, you can stick to part I and III, just skip part II.
Part I: Current Practice and Utopia
As a radio journalist, I spend a lot of time listening to audio over and over, choosing what to cut out and what parts to keep in, and how to rearrange the audios I have. This is a very rewarding process, as well crafted features and reports can engage the senses in a very artful way when done right. But it is also a extremely time-consuming process. Editing audio up till now meant, editing in the same spead as you can listen. This means that with a industry-standard DAWs and Audacity/Tenacity, you'd need at least one hour to edit a one hour interview, depending on how many edits are necessary, the amount of time needed will easily skyrocket.
I admit to usually editing at 1.25x to 1.5x the normal playback speed, and I've gotten quite fast in editing decisions, so I'd usually need 40-50 minutes for that same hour long interview. Now we've got this crazy little thing called "AI", which gives us some fancy tools that appear to halve that editing time. Okay, quick disclaimer: I'm not talking about these fancy programs editing for me, I do actually want to retain creative control, after all. But thanks to large language models (for our purposes: speech recognition), we can now easily let the computer automatically transcribe our audio, so why not just edit the resulting text, and then tell the computer to adjust the audio accordingly? This, in essence, is the application of paper cut editing to audio production. And let me tell you, it's awesome! At least for me, I work a hell of a lot faster with text, which comes as no surprise as most people read double as fast as we speak.
So, what's the great Idea? Well, editing on paper is the fastest and most easy way I know to work on complex stories. But I'll let Prabhas Pokharel explain:
Paper editing is a process in which you review transcripts, identify the quotes you'll want to use, and lay out the story using the dialogue. The final product (the "paper edit") consists of quotes from the transcripts, arranged in order.
Radio journalists working on a story will often transcribe audio snippets from interviews, print them out and then physically arrange them, adding some more text as they go. A more demanding story, integrating several interviews and other audio snippets, can quickly grow to several meters of taped together paper. Believe me, I've seen it and I've done it, and it helps greatly (though we'll usually be doing it in a text editor, I mean, it's the 21st century after all, even if we're still waiting for our hoverboards...).
So paper editing is great, but with audio it's a lot of work. You can't just copy/paste a quote from some official statement in the internet. So instead we need to pick the audio snippet from an interview, which requires listening to the audio until we find the right part, and either transcribing it completely or summarizing it for our paper edit. And once we have our finished script, we still nead to craft all the audios together with our favorite digital audio workstation, once again listening a lot to these audios. A lot of this could be automated, the creative process is mainly the act of editing and the finer tweaks in the final audio production.
So what we want, for paper editing to be easily applicable for audio production is the following workflow:
Autotranscribe Audio → Edit in Textfile → Autocompile Roughcut → Postproduction → Publish.
Thanks to advances in publicly available large language models, transcription can now be automated. And thanks to Scateu we can take a command line linux text editor, Vim, and make it do the actual edit in textform and than automatically create our audio rough cut.
Part II: How does this work?
Well, all in all, it's just a great combination of well established, simple tools, Whisper and some useful scripts to glue it all together. I'll only give instructions that work on linux, as that's all I've tried. The main work on Vim is from Scateu's Github page, where you'll find info on using this on Macs and I've gotten some helpful pointers from Zach "earboxer" DeCook. Thanks, y'all!
Here are the programs you'll want to install with your favorite linux package manager or the one your linux distribution of choice happens to come with:
dos2unix sox ffmpeg jq socat vim mpv whisper.cppWhisper.cpp is the implementation of a large language model for transcribing audio. Depending on your linux distribution, you also might need to install the relevant model for whisper, either small, medium or large. The larger the model, the better your transcriptions will be, but you'll also need more space on your harddrive. I've had good results with medium so far. You could also use some other large language model implementation, as long as it can give you .srt files (subtitle files with timestamps). To get the rest of the software and scripts we want to use, run the following commands in a terminal:
$ mkdir -p ~/.vim/pack/plugins/start; cd ~/.vim/pack/plugins/start
$ git clone https://github.com/scateu/tsv_edl.vim
$ git clone https://github.com/vim-airline/vim-airline
$ git clone https://github.com/pR0Ps/molokai-dark
$ cd ~/.vim/pack/plugins/start/tsv_edl.vim
$ make install-utilsNow with set up vim with all the gadgets it needs to be able to process audio editing too! But, for audio editing, we should change one setting: We want crossfades where cuts happen, for smooth transitions instead of jarring cuts.
So: Open the file "ftplugin/tsv_edl.vim" in a text editor and go to line 237. Here you will find two lines that look like this:
"vnoremap :w !tsv2roughcut --ask-before-delete-temp-files --user-input-newname --play --audio-crossfade
vnoremap :w !tsv2roughcut --ask-before-delete-temp-files --user-input-newname --play
We want to uncomment the command with audio crossfade, and comment out the line without crossfades. Change this to read:
"vnoremap :w !tsv2roughcut --ask-before-delete-temp-files --user-input-newname --play --audio-crossfade
vnoremap :w !tsv2roughcut --ask-before-delete-temp-files --user-input-newname --play
And we're set. Next: Let's try this!
Open a terminal, navigate to where your audios are. You'll need .wav audio files, with a samplerate of 16khz for whisper to be able to process them (Why? no idea.). In case that's not your default (and it shouldn't be, please always work with at least 44100khz), this is how you can make any audio fit whispers requirements:
$ ffmpeg -i [NAME_OF_YOUR_ORIGINAL_AUDIO] -ar 16000 [NAME_OF_YOUR_NEW_AUDIO].wav*Side note on audio quality: If you dump your 44.1khzwavs somewhere safe, and then switch out the lower quality files we needed for transcribing them with whisper after you have your transcriptions, then you will be editing the better quality files!
Creating the correct audio files should be quite fast. Then we can watch the magic happen:
$ whisper-cli -m /usr/share/whisper.cpp-model-medium/ggml-medium.bin -f [NAME_OF_YOUR_AUDIO].wav -osrt -l german --print-colorsThis should take a while, depending on your hardware. A good old X260 Thinkpad will take roughly as long as the audio is long, go get some coffee. Ah, and while we wait: What does this command so?
- Whisper can use different models for predicting text from audio. The larger your model, the better the results. The command "-m /usr/share/whisper.cpp-model-medium/ggml-medium.bin" tells it to use the medium model, which under Archlinux can be installed as a package (in the AUR) and will then be placed in /usr/share. If you download it manually, it'll be in the directory where you put it. Models that end on -en have only english language training data.
- The "-f" tells the programm that it will now get fed the filepath to the audio it's supposed to transcribe.
- the "-osrt" tells Whisper to output the transcription in the .srt file format, which is a standard subtitle file format, where the text is also aligned with timestamps when these words appear in the audio. We need these timestamps to be abe to edit the right spots in our audio later.
- "-l" is the language modifier. Default is english, just wanted to show that you can also use it for german.
- "--print-colors" tells whisper to color-code our text depending on how sure it is if it's guessed the word correctly. Green is a high probability, red is low. This gives you a nice estimate of how much corrections are necessary later on.
Pro tip: You can also tell it how long or short the text snippets per line are supposed to be with the modifier "-ml" followed by the number of characters you want per line.
Ah, the whispers have stopped? Great, you'll now have a .srt file of your audio, read through it and compare to the audio to get an impression of how well this works! Before we start editing, we have one last command to perform:
$ srt2tsv [NAME_OF_YOUR_AUDIO].srtThis will create a .tsv file. These are similiar to the .srt file, just formatted a bit differently so that it's easier for our text editor to work with them when editing audio. And now we can edit:
$ vim [NAME_OF_YOUR_AUDIO].tsvYes, Vim is weird and nobody should use it...but it's what the nerds scripted an integrated audio playback for, so lets get to it. If you've never used Vim, like any normal person, it's not your usual text editor. To actually edit text, you'll have to press "i" and enter "insert mode", before you can type. The escape key gets you back to "normal" mode, where you can give Vim commands. To close Vim, type ":quit", although if you haven't changed the opened file you'll need to add an "!" to that. Fun stuff! A tutorial on Vim can be found here.
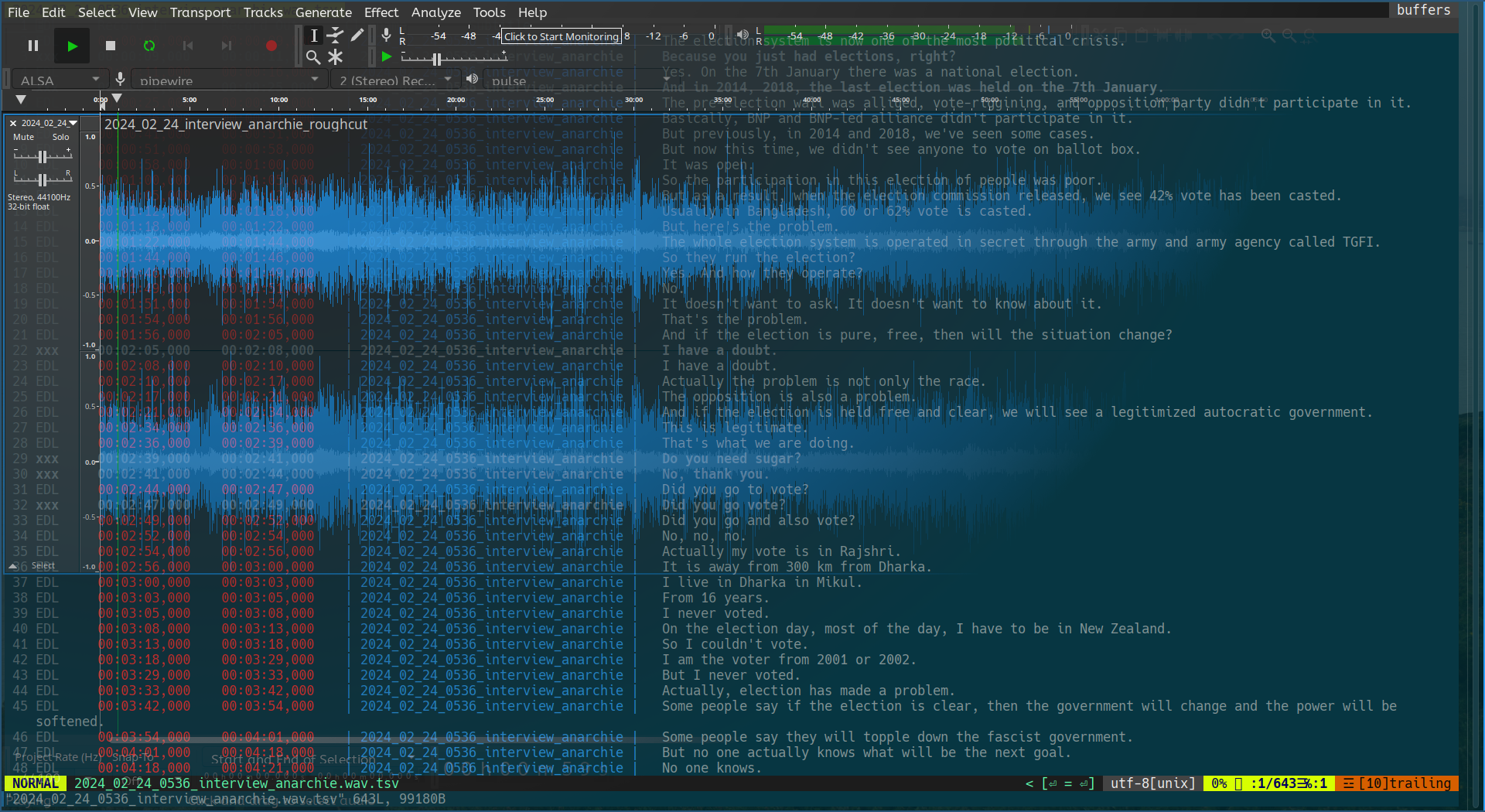
What is important is: There's a bunch of keys that do things we want to edit our audio. We can move up and down the lines with the arrow keys, and we can cut lines with backspace (the "EDL" in the beginning will become "xxx" to indicate that this line will be cut). And the best part is, we can also listen to the audio to check if we're cutting at the right space, but for that we need to do one small thing: We need to remove the ".wav" from the filename in every line, between the timestamp and the transcription. Find & replace should do the trick, here is the vim command you want:
:.,$s/filename.wav/filename/The ":" tells Vim that we're issuing a command, the ".,$" tells it to search in the whole document for every occurence, the "s" tells it to search, and then we have the search term followed by the replacement term, seperated by "/".
Now we can also listen to the line currently below our curser with Shift + Tab (as long as the audio file is in the same directory). Now you probably can see how editing this way is so blazingly fast, just skim the text and delete lines you don't need, and listen in at any point as needed... there's obviously a bit more, here is the reference card for audio editing with vim for delving deeper into the magic. You can even copy and past different lines from different transcripts together into one new file, adding some script in between for the narration, thus creating a classic composed programm, which could look like this:
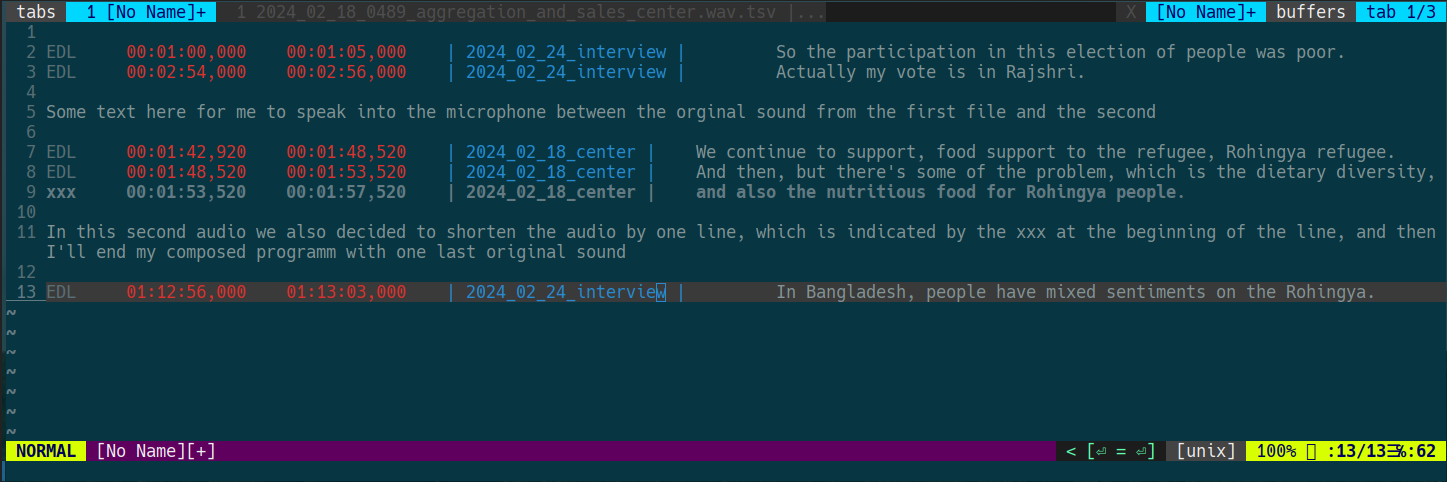
To now create the actual edited audio file, we can select all the lines that we want to process for our audio with the shortcut "V" (add lines by moving the cursor along) and pressing the spacebar. Any lines marked "xxx" in our selection will be cut from the audio. Vim will ask us how to name the new file (yes, it's none-destructive!) and then it will create the audio for you. If you also recorded, transcribed and inserted your own narration you can even create complete roughcuts of a complete composed programm or feature, not just interviews.
Part III: Some Insights and Ideas
So obviously, editing audio like this is huge news. Not just because it only took me ~40 minutes to cut a two hours long interview (it's now one hour and 17 minutes long), simply because reading is just so much faster than listening, but also because it's possible to also combine several audio files, cherry pick lines you want to use and arrange them according to your narrative idea, then even adding newly recorded narration, before the computer edits everything together for you. In this way any format that isn't live, like reports, interviews, composed programs and features can be created in a more focused manner.
I believe the workflow for radio journalism will greatly improve through this method in the long term, and it's awesome that linux users can now do this with Whisper and Vim, while the BBC is still testing it's own approach as an internal beta (as of March, 2024).
It's not just the workflow that could improve, I also see huge advantages for cross-media publishing, as it would be a piece of cake to do one last correction of the complete script and publish your story as text and audio on your respective media website, even adding automated translations for more languages. The potential for multilingual and accessible journalism is definetely worth working towards.
Still, there are some drawbacks currently. Let's address those now.
First, the most obvious problem: As this write-up shows, there's a lot of technical expertise involved (the linux command line and Vim), which requires substantial motivation for people who aren't developers or tech enthusiasts. Although I believe many people could learn the current workflow, I can quarantee you from my experience in the world of community radio that many will refuse. This isn't ill will, these people are very dedicated and nerdy in their own area, creating many wonderful hours of radioshows in their free time. But making radio is something a very diverse group of people do, and to enable them to do that, they need software that just works (and stays the same over the years). If someone would craft the same features described here onto any traditional GUI-based text editor with clickable icons, I'd see no reason why people won't immediately start using it. So maybe someone want's to add whisper support to Audapolis? Give me a shout if you do, I'd greatly appreciate it!
Secondly, having a rough cut is great, and as radio journalists, it's no problem to then do one more production round. But, the default settings don't apply crossfading when cutting the audio, which leads to jarring cuts - be sure to change that setting as described above. Crossfades might even make many rough cuts become final cuts by default (apart from a bit of volume work, EQs and dynamic effects). But it will always be necessary to fire up a digital audio worstation and at least check if not correct transitions, volume and stuff like that. Thinking about this lead to another thought: Would it be possible to also create an Audacity/Tenacity or Ardour project file, with the audios on alternating tracks, completely prepped for a last round of edits and postproduction? If anyone can do that, I'll gladly test and debug it!
Third, and less in regard to the workflow and Vim itself, but more in regard to the automated transcription. Whisper is neat and all, but obviously it will produce mistakes or miss important parts of your audio. Mistakes can be as simple as switsching 19 out with 90, can sound quite similiar but mean vastly different things. Using LLMs for easier access to recordings and relying on it are two very different things. Going forward, it will be essential for radio journalists like me to also double check that we're not missing important parts of our stories just because we're only working with what the LLM could extract from our recordings. A combination of notes on important aspects we notice while gathering our material in the field and double checking audio transcriptions and the source material should go a long way here in adressing this issue, but it's essential that we take the time needed for this double checking of our work. In the best case, somebody else should always double check your work - this needs to become a journalistic standard asap. Never forget, working as a journalist means due diligence, checking your sources and making sure the stories you tell are not just meaningful but also factual. No so-called "AI" can replace this part of journalistic work. Let me illustrate this point in one closing example. I have one whole interview that is clearly audible and understandable for human ears, but the transcript looks like this:
00:27:42,000 00:27:52,000 [background noise]
00:27:52,000 00:28:02,000 [background noise]
00:28:02,000 00:28:12,000 [background noise]
00:28:12,000 00:28:22,000 [background noise]
< No more Linux Mobile | Punk in der DDR >