Further thoughts on (Paper-Cut) Audio Editing
April 8th 2025 | #English #Open Source
A year ago I wrote a blog post on editing audio with the text editor vim, so transcribing audio and then editing the text output and apllying these changes to the audio file. A process that for me greatly speads up my workflow as a radio journalist, as I read faster than I can listen (sanely) to an audio file. I got inspired to search for a tool for this by the BBC's forray into this field and I called it "Paper Cut Audio Editing".
Well, to my surprise my original writeup garnered some attention - from Scateu, who implemented crossfades in his vim extension (Thank you soooo much!) and from one person from Audacity who told me about them implementing transcription through the OpenVino plugin and their seperate product which allows text based editing called Descript. Obviously I've also worked with this workflow some more during the last year, even having developed a workshop on it. I've also updated the original writeup with up-to-date instructions on enabling crossfades and how whisper works, as the command has changed since then. So here's a nice collection of good-to-know-information around the topic!
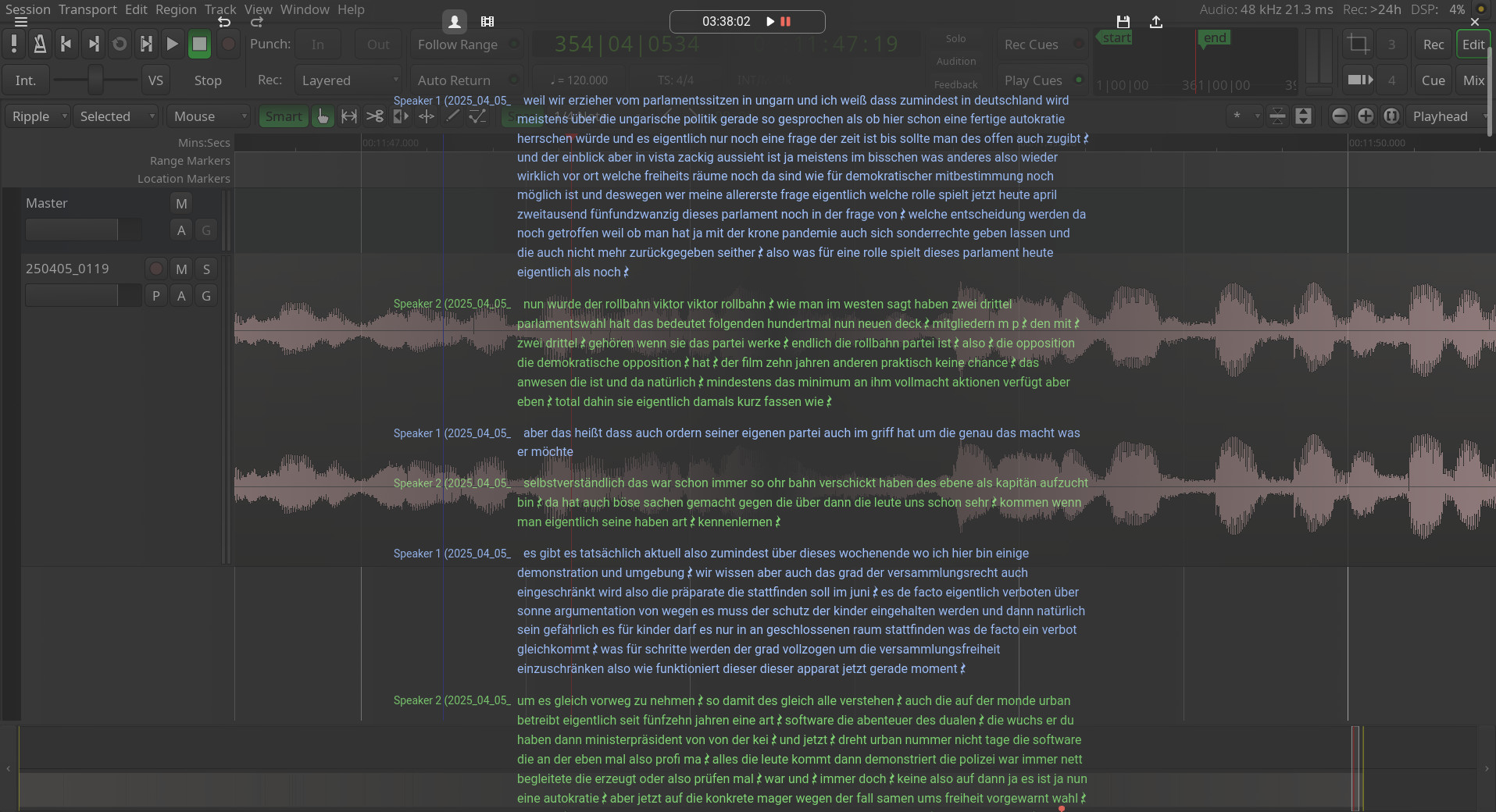
So first things first: I still prefer working with Vim for this, as all the features I need are there, and it's the closest I've come to an all-in-one solution. I've used it for all my work on Bangladesh like this or this or this audio report. So what's left for the vim workflow to be great for me? Well, it's pretty much that guessing timestamps when splitting a line is not good enough for really fast editing - having timestamps per word would be an alternative, but then the .tsv file becomes unreadable. If there's any fancy workaround for that, let me know!
This issue is something I noticed when working with Descript, where I can easily delete single words or complete lines without having to adjust timestamps by hand.
The commercial alternative
Descript is a text-based editor for audio and video that aims to provide one simple unifed user interface that is easy to use for people who don't want to deal with command lines and vim. This is great! And it works. I've played around with it a bit and you can easily edit interviews and paste together composed programms from multiple source interviews and even record new audio on the spot or write a script in between your audio parts - everything you need. It also does speaker recognition, so you always know who's talking, and you also have a waveform, to take a look at the original audio. There's also a neat toolset, like detecting and removing filler words or AI-assisted sound cleanup, or letting an AI speak words you just scripted for you.
So why don't I use it? Well for one, it's not free to use - a free account only gives you 1h of transcription per month. THen there's the fact that it's "in the cloud" - fancyspeak for you don't control your own data and it can be used for AI-Training or other stuff. No matter what they currently use it for, depending on profit motive of the company, this can change - for a journalist working with sensitive material, this is a no-go. Also it's not open source, so not part of the digital commons. Finally, it makes it to easy to choose unethical shortcuts - like generating a voice for a written quote, imitating a reality that never existed (if somebody only wrote something, I can't just pretend like he said it), or removing all filler words instead of consciously cleaning up speach without changing the way someone speaks. This closely relates to Descript's feature creap. It can do so much, that it feels cluttered and messy to work with for me.
The classic editor
So maybe whisper-powered transcriptions in Audacity with OpenVINO are the open-source solution! It adds an analytics tool to Audacity, where you can generate a transciption of an audio from your project, which will then be added as text markers. This is good enough for editing interviews, but reading the textmarkers isn't as fast as standard text, as they're aligned from left to right along the audio and sometimes overlap. Also, you have to be careful to cut the audio and the textmarker tracks, or they get shifted and don't correspond to the right audio anymore. Limited use, but nice! Although OpenVINO is again only available on Windows. So it's not an option for me, as I ditched windows years ago and seeing how data hungry and AI infested it has become I will definetly never switch back.
The open source tool
The good news: There is an open source paper cut editing tool, called Audapolis. It has a sleek interface, you simply import your audio, it transcibes it, and you can then remove and correct words and copy & paste from one document to the other or extract small sound bites without any issues. While I was working from Zagreb last winter, I used it to quickly skim interviews for quotes for newspaper articles, like this one, and composed radio programs like this one or my series on Antifacism in Croatia, to then extract exactly that part I needed for the story I was writing.
The bad news: It still uses a pre-ai transcription programm, so it produces decidedly more errors in it's transcriptions, so not optimal for longer translations. Also, it was developed with funding, which then dried up and there haven't been any updates since. Today, it crashes often, and saved files can get corrupted, making it impossible to continue working on the same project if you're unlucky. If someone were to switch out Vosk for Whisper and do some bug hunting, this would be a clear winner for ease of use, feature richness and scaleability in the community radio field. If you'd like to work on that, get in touch and I'll do everything to help out short of learning to code.
Last thoughts
So that's some options to try out. Having played with this workflow for a while now, there's also one point I really want to make clear:
Paper cut editing is great for working on interviews, translations and composed programs. It's good for speach based informative audio - it's absolutely not suited for radio art of any form. The creative process of creating features and radio plays requires working with the original sounds - including noises, not just speach - to guide the editing process. Utilizing text-based workflows will shift that to a content-focused workflow, removing the auditory relationship between you, your material and the story you're trying to tell.
< Die Suche nach einer linken Perspektive für die Ukraine | Menschen auf der Reise: Die Lage an der Grenze in den Westalpen >